

Assumed Audience: Students and early-career developers new to continuous deployment, especially those with experience limited to local development. Readers familiar with the previous post in this series will find it easier to contextualize the examples discussed here.Introduction
In our previous post, we explored the full production world of the Quiz Engine (QE), covering both the backend and the frontend setups. We examined why transitioning from a local environment to production is crucial for handling real-world usage and ensuring reliability. The backend leverages AWS Lambda and API Gateway, while the frontend is hosted on S3 and served through CloudFront. Along the way, we touched on the importance of GitHub workflows and infrastructure templates, which help maintain continuity and consistency in production deployments. Understanding these fundamentals is key because, in this post, we will frequently make allusions to QE’s deployment for comparative analysis.
Now, we’re expanding our scope to look at a range of progressively more complex production setups. We will start with examples of server-side rendering, then move into quicker deployments with Amplify, and gradually work our way towards more customized environments with greater control. As we advance, you will see how these setups offer increasing flexibility and choices, but also come with added complexity and effort.
What’s important to remember is that none of these approaches is perfect. The craft of production deployment involves navigating trade-offs and ambiguity. There is a lot of freedom to experiment, and that openness can be both daunting and thrilling. While some approaches may be more resource-intensive (time, money, effort), the process of exploring and refining them will ultimately make you a more thoughtful developer. Especially in an NGO context like ours, where making technology work in low-resource settings is paramount, these considerations matter deeply.
In my opinion, framing deployments solely around cost optimization, efficiency, and other functional purposes feels limiting. It reduces the experience to a rigid, brutalist pursuit. For me, the excitement comes from the joyous combinations and the unexpected curveballs this world throws at us, all the more so because it is a direct window into interacting with thousands of users. I know that merely sprinkling the word “joy” here doesn’t guarantee anything! This post is an attempt to substantiate and share the daily joys I experience as I work through the nuances of the production world.
So, buckle up for a whirlwind tour of some of Avanti’s products. The goal isn’t to just showcase these tools but to emphasize that the production world is fun, creative, and insightful.
Reporting Engine
In the previous post on QE, we never really questioned why we used the VueJS framework. Why not simply write the HTML, JavaScript, and CSS files and serve them directly via the backend? The key reason lies in the interactivity and dynamism of QE’s frontend.
For example, users can click multiple buttons — like Previous, Clear, Next, and Submit — and instantly see changes reflected on the screen. While it is possible to write this type of logic in plain JavaScript, VueJS eases effort with its support for reactive components, making it simpler to manage computed values and dynamic updates. Furthermore, using separate frameworks for the backend and the frontend allows for judicious separation of concerns.
 and a Report Page (Right). Notice the variety of options available on QE as compared to a relatively static RE.")
But what if the frontend doesn't require such intricate logic? Could we serve it directly from the backend? The answer is yes, and the practice is known as server-side rendering! Avanti’s Reporting Engine (henceforth RE) is an example of this approach.
Once students complete a quiz, we fetch their answers from MongoDB, compute various metrics such as ranks and percentiles, and sync the results to BigQuery and DynamoDB. The results are then shared with students through parameterized RE links, structured as https://reports.avantifellows.org/reports/student_quiz_report/{session_id}/{user_id}, which pull data from DynamoDB. With its fast read operations and low latency, DynamoDB is a reliable database choice for handling this use case efficiently.
RE uses a FastAPI backend too, but it differs from QE’s backend in a crucial aspect. In QE’s backend, we retrieve data from MongoDB, returning it as a JSON response. By contrast, in RE’s backend, we retrieve data from DynamoDB and directly return an HTML page to the user (Code Snippet 1).
---------------
Code Snippet 1: Comparing the logic of QE backend and RE backend.
Notice that we directly respond with an HTML page in the latter case.
---------------
# QE backend pseudocode
def get_quiz(quiz_id: str) -> JSONResponse:
quiz = mongo_quiz_collection.find_one({"_id": quiz_id})
return quiz # json
# RE backend pseudocode
def get_report(user_id: str, quiz_id: str) -> HTMLResponse:
report = ddb_client.get({"user_id": user_id,
"quiz_id": quiz_id})
return HTMLTemplateResponse(
template="report_frontend.html",
content=report) # html fileTo productionize RE, we follow similar templates and commands (sam build and sam deploy) as QE: we deploy FastAPI code to a Lambda function and add an API Gateway layer on top. This provides us with a URL that includes throttling capabilities. There is a slight twist, though. RE's backend responses are fairly static and can be cached. Caching stores static responses on Amazon's servers close to users, improving load times. We therefore add a CloudFront distribution (just like we did for QE's frontend!) on top of the API Gateway and map the customized subdomain https://reports.avantifellows.org to the CloudFront URL.

Futures Tool
In the previous example, we responded to user requests with simple HTML files. Can we do better, and respond with bespoke components that offer more dynamism on the user’s screen? For instance, imagine a function that returns a table of scholarships with interactive features like searching and sorting, based on the user's input criteria:
---------------
Code Snippet 2: Server-side rendering of reactive components. Is this possible in Python?
---------------
# pseudocode
def get_scholarship_table(input_grade, input_category):
scholarship_list = client.get({grade=input_grade,
category=input_category})
return ReactiveComponent(template="TableComponent.vue",
content=scholarship_list)Here, a simple HTML response wouldn’t suffice because the user expects real-time updates without refreshing the page. Unfortunately, Python, unlike JavaScript, cannot render these client-side behaviours.1
Enter NextJS, a framework that allows for server-side rendering using a NodeJS backend with a ReactJS frontend. Our Futures tool is a simple NextJS application that sifts through rows of data from Google Sheets and returns data matching the user’s filters. So far, we have implemented two main features: (a) listing relevant colleges based on an input rank, and (b) displaying relevant scholarships that match input criteria like category and family income.

To productionize the Futures tool, we use yet another AWS product Amplify, which connects directly with our GitHub repository. Amplify detects each code update and deploys the latest version. Effectively, Amplify automates the entire CD process, eliminating the need to design infrastructure templates or write deployment workflows. Behind the scenes, Amplify likely assembles a stack consisting of Lambda (with a NodeJS environment), API Gateway, and CloudFront to deploy applications. We still have to set a mapping on Cloudflare, though.

Amplify’s ease of use makes it a tempting choice for all deployments, but it is not without trade-offs. In exchange for a fast, hands-off deployment process, we give up fine-grained control over many settings. Amplify uses default configurations that work well for many general web applications, but these defaults may not always suit our specific requirements. Moreover, tweaking Amplify’s internals is non-trivial and may require the assistance of Amazon’s developers.2
Portal
Some of our tech also resides outside AWS! Particularly in Google’s Cloud Functions, which is quite similar to AWS Lambda. Both services allow us to run small scripts in response to events without managing servers. Strictly speaking, the backends of QE and RE we’ve discussed earlier are not typical use cases for Lambda (they are Lambdaliths!). Lambdas (or Cloud Functions) usually shine in scenarios where small, event-driven tasks need to be executed quickly.
A more typical example would be triggering atomic tasks upon user login, such as checking the user’s ID or verifying their birth date. At Avanti, login happens through Portal, an authentication service that authorizes user access to nearly all our resources.
Initially, we handled these tasks with Cloud Functions because our user data was stored in Google’s Firestore, which integrates well with Cloud Functions. When a user logged in, functions like checkBirthdate or getGroupData were triggered to validate login credentials.

We eventually moved away from Cloud Functions as we migrated our user data from Firestore to PostgreSQL. This transition gave us more control over our database, allowing us to build a custom DB service. With PostgreSQL, we have more flexibility in managing user data and integrating other workflows, such as feeding data into BigQuery. PostgreSQL’s relational model also suits our needs better as we scale, providing us with richer query capabilities and control over indexing, transactions, and connections between tables.
ETL Flows
As we remarked in the previous post, Lambda has its limitations such as restricted environment control and a small selection of libraries. These limitations become particularly apparent when dealing with more complex ETL flows, like the ones we use to transfer data to DynamoDB (for reporting) or move data from our database to BigQuery. Our ETL flows require bespoke libraries and more flexibility than what Lambda’s default environment offers.
To overcome these limitations, we use a more customized approach by leveraging Docker and Amazon ECR (Elastic Container Registry). This allows us to define our own environment within a Dockerfile, which describes the machine setup, operating system, necessary packages, and environment variables. Once the Docker image is built, it is uploaded to ECR, and we use this image to create Lambda functions with specific runtime environments and libraries.
---------------
Code Snippet 3: Dockerfile pseudocode for ETL Lambda
---------------
# Start with a pre-defined lambda environment as base
FROM public.ecr.aws/lambda/python:3.9
# Copy files
COPY lambda_function.py .
COPY requirements.txt .
...
# Setup environment variables
ENV DDB_URL="https://dynamodb.ap-south-1.amazonaws.com"
...
# Install application requirements
RUN pip3 install -r requirements.txt
# Command that specifies entry point to lambda code
CMD [ "lambda_function.lambda_handler" ]The deployment process with Docker and ECR is straightforward. In our GitHub Actions deployment workflow, we first build the Docker image, push it to ECR, and then create or update the Lambda function with this new image ({id}.dkr.ecr.ap-south-1.amazonaws.com/folder-with-dockerfile) instead of the default image (public.ecr.aws/lambda/python:3.9):
---------------
Code Snippet 4: Deployment using ECR + Lambda
---------------
# 1. Build Docker Image
docker build -t folder-with-dockerfile
# 2. Push Docker Image
docker push
{id}.dkr.ecr.ap-south-1.amazonaws.com/folder-with-dockerfile
# 3. Create/Update Lambda Function With New Image
aws lambda update-function-code
--function-name complex-lambda-function
--image-uri {id}.dkr.ecr.ap-south-1.amazonaws.com/folder-with-dockerfileWe use Amazon SNS (Simple Notification Service) to trigger the dockerized ETL Lambda. With SNS, we can efficiently trigger multiple functions or services (called fan-out) in response to a single user-generated event. For instance, say we want to convey the timings of the latest sync to our operations team on Discord. We could use SNS to not only trigger the ETL flow but also inform a Discord bot to push a notification on the operations channel. Thus, SNS allows for a more decoupled architecture.3

While the setup in Figure 6 provides significantly more flexibility than Lambda’s default environment, it is worth noting that it still doesn’t offer the same level of control as an EC2 instance. For one, we cannot manage low-level system tweaks and network configurations. More crucially, cold start times may increase since Lambda has to initialize the Docker container, which can slow down performance for time-sensitive tasks. Lastly, for those new to the technology, maintaining and updating Docker images has a steep learning curve.
AF Scripts
At times, we may need Lambda functions to run at a regular cadence, independent of user-generated triggers. For example, users are constantly signing up for our products, and we need a Lambda to run at least once a day to sync the new users’ information from PostgreSQL to BigQuery. There are a couple of ways to achieve this: (a) a developer dutifully sends a message to SNS every day, or (b) we set up Amazon’s EventBridge to schedule triggers.
An alternative, aligning with our post’s trend towards more control and flexibility, is to save the requisite script on an Elastic Compute Cloud (EC2) instance and schedule triggers using crontab. Briefly, an EC2 instance is like any other full-fledged computer: we can choose the operating system, the available storage, and the computational power. It is a virtual machine that is active throughout the day and can be accessed remotely using the ssh (Secure Shell) command, colloquially referred to as SSHing into EC2.
We first create an EC2 instance with our preferred architecture (in this case, a t3.large instance running Ubuntu 20.04 with 16GB of memory). Once the instance is live, we ssh into it and create a directory (~/af/scripts/ here) to store our scripts. Using a simple GitHub Actions workflow, we can continuously deploy updated scripts to this folder on EC2:
---------------
Code Snippet 5: Continuous Deployment of scripts folder to EC2
---------------
# Add Script to EC2
rsync -avh -e
"ssh -o StrictHostKeyChecking=no -i private_key"
sync_postgres_to_bq/
${USERNAME}@${HOSTNAME}:~/af/scripts/sync_postgres_to_bqBut how do we automate the running of this script on a daily basis? This is where crontab comes in — a simple yet powerful tool that allows us to schedule tasks at specific times. In the EC2 terminal, we open crontab and set up a task to run the script every day at a specified time:
---------------
Code Snippet 6: Crontab task to sync PostgreSQL data to BQ daily
---------------
# Open crontab
crontab -e
# Run sync_postgres_to_bq script (https://crontab.guru/)
0 21 * * * cd af/scripts/sync_postgres_to_bq && bash run.shIn fact, we use crontab to schedule several scripts on our EC2 instance. The inputs and outputs may vary, but all scripts follow a similar structure shown in Figure 7. Some more examples: a script to sync MongoDB data to BQ (daily twice), a script to save snapshots of MongoDB production database to S3 (monthly once), a script to trigger a discord bot that informs our tech team about active EC2 instances (daily once), etc. In my opinion, despite the seeming simplicity, these scripts belong to the production world too, as they influence our production databases with tangible outcomes.4
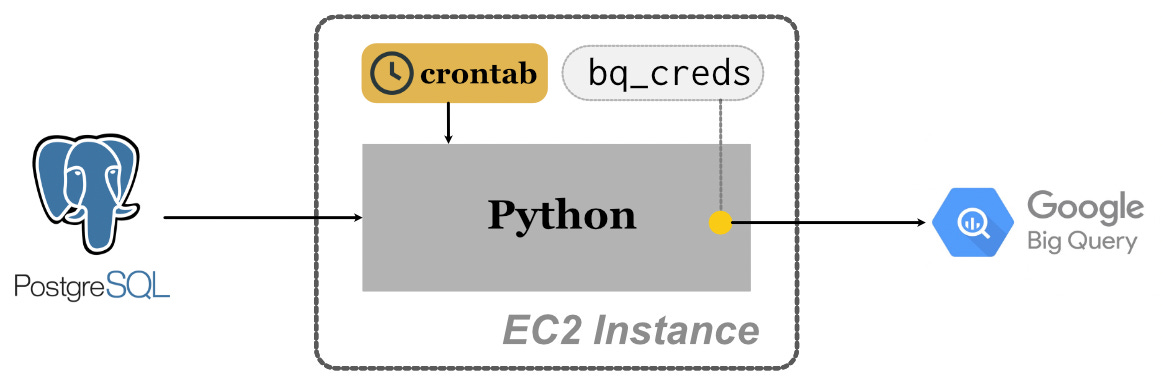
Hosting Services on EC2
We’ve already covered quite a lot in this post! Before we wrap up, here are some brief remarks on one last important use case: hosting web services on EC2 and making it publicly accessible via a custom domain.
We assign an Elastic IP (static address for dynamic compute) to the EC2 instance and map this IP to a Cloudflare custom URL. We need an Elastic IP because the address of EC2 instances keeps changing every time we start/stop it.
An issue we often encounter is that services on EC2 may run on non-standard ports that are not intuitive to users. For instance, Grafana, an open-source visualization service, runs on port 3000, meaning users would need to type something like https://example.avantifellows.org:3000 to access the service. This isn't user-friendly because most users expect a clean URL (like https://example.avantifellows.org) without needing to specify a port number. To address this, we use Nginx as a reverse proxy to map port 3000 to port 443 (default port for HTTPS traffic), allowing users to access the service with a clean, standard URL.
For more information, Aman Bahuguna from Avanti’s Tech Team has a detailed post with code snippets on hosting a Pheonix application (port 4000) on EC2.
Final Remarks
Where to go from here? The best next step is to build a web service and test it out. AWS Free Tier is a great option for getting hands-on experience without spending much. If you are unsure of what to create, even a personal website on GitHub Pages can serve as an excellent avenue for experimentation. The idea is to take something you’ve built locally and bring it to the world, learning along the way.
For those wanting to dive deeper, there is a wealth of excellent resources available. Books like The Good Parts of AWS offer a more detailed look into the inner workings of cloud infrastructure. They prompt you to carefully reconsider your daily decisions and give you a greater appreciation for the intricacies involved.
Another resource I’ve found incredibly useful is a four-part series on how Ars Technica is hosted. It is a comprehensive, real-world case study that covers much more than what we’ve managed in these two posts. I’ve returned to it many times, and in many ways, it inspired my write-up. Real-world deployment examples are plentiful online and present practical challenges rather than just abstract trade-offs.
For those who prefer video format, Gaurav Sen’s system design videos, such as this one on Instagram’s architecture, are packed with insights. Though geared towards interview preparation, they are simple and effective, offering great clarity on system design choices.
You’ll notice many of these resources frequently mention concepts like Load Balancers, VPCs, and Security Groups — topics we didn’t explore here at all. These are critical parts of production deployment, and while we do use them, they didn’t quite fit the flow of this post. Including them would have made the post prohibitively long. However, these topics are incredibly important, and we hope to write about them in a future post, perhaps when we soon launch the new backend for QE.
Putting this series together has been a fruitful experience for me. I hope I’ve managed to transmit at least a part of the fondness I feel for the production world and its limitless possibilities.
Acknowledgements
Thanks to Deepansh Mathur, Pritam Sukumar, and Aman Bahuguna for their substantial guidance and patient corrections of my misunderstandings about production environments. I also appreciate reviewers Ankur Doshi, Drish, and Abhinav Gupta for their insightful feedback, which significantly enhanced the presentation of this post.
I used ChatGPT’s assistance in refining the prose of some sections. For diagrams, I used the Affinity Designer tool.
If you spot any errors, have suggestions for improvements, or wish to contribute to our repositories, please reach out to us on Avanti’s Discord channel: https://discord.gg/aNur9VPS2r
Additional Resources
Are Lambda-to-Lambda calls really so bad?, by Yan Cui (https://theburningmonk.com/2020/07/are-lambda-to-lambda-calls-really-so-bad/)
A Step-by-Step Guide to Creating Load Balancer and EC2 with Auto Scaling Group using Terraform, by Sharmila S (https://sharmilas.medium.com/a-step-by-step-guide-to-creating-load-balancer-and-ec2-with-auto-scaling-group-using-terraform-752afd44df8e)
Migrating To Hugo, by Vicky Boykis (https://vickiboykis.com/2022/01/08/migrating-to-hugo/)
Just as I was wrapping up this section, a new Python-based web framework called FastHTML made its appearance. Ironically, it allows us to create expressive and interactive web components — something I had just pointed out as Python’s weakness!
Vercel is another widely used option for deploying NextJS applications. Amplify, though similar to Vercel, provides additional integration with other AWS services (like CloudWatch), which can be advantageous for certain use cases.
A more comprehensive architecture is [Input → SNS → SQS → Lambda]. This setup allows the input to be distributed to multiple subscribers (fan-out) via SNS, rather than limiting it to a single SQS queue. Additionally, Lambda can process events from the queue in batches, enhancing consumption speed. Moreover, failed events can be added back to the queue for subsequent retries.
We can avoid the hassle of SSHing or configuring settings on AWS Console by automating the entire EC2 instance creation, folder setup, and even the insertion of crontab commands using Terraform or similar architecture-as-code tools. Admittedly, this approach involves additional complexity and is beyond the scope of this post.